Selecting buildings on tiles
TL;DR: I'm working on a map search project, where you can find a place in the world by a vector drawing or raster sketch or even textual description (maybe in the far future). Now I'm exploring ways to generate feature vectors for indexing. Why not graph neural networks or embeddings? I have only basic integrated GPU, so I want to try something simple first. Anyway, embeddings and graph networks or just feature vectors, the workflow will be the following:
- Index: OSM → DuckDB → Tiles → Vectors → Index
- Search: Drawing → Vectors → Tiles (from index) → Refine with computational geometry
Selection
User won't draw all geometries from the tile, only some of them - that's why I decided to build a feature vector for all possible object combinations. Of course, the idea of generating all 2n subsets looked way too slow and I made an assumption: user will most likely draw only neighboring objects (exceptions?).
But how to select a neighbor? I decided not to go with KNN or simple Cartesian distance, because it requires either a fixed distance or fixed K and it won't work when the tile is too sparse (farm with a house and a shed) or too dense (old city). First thing that came to my mind was Voronoi diagrams,
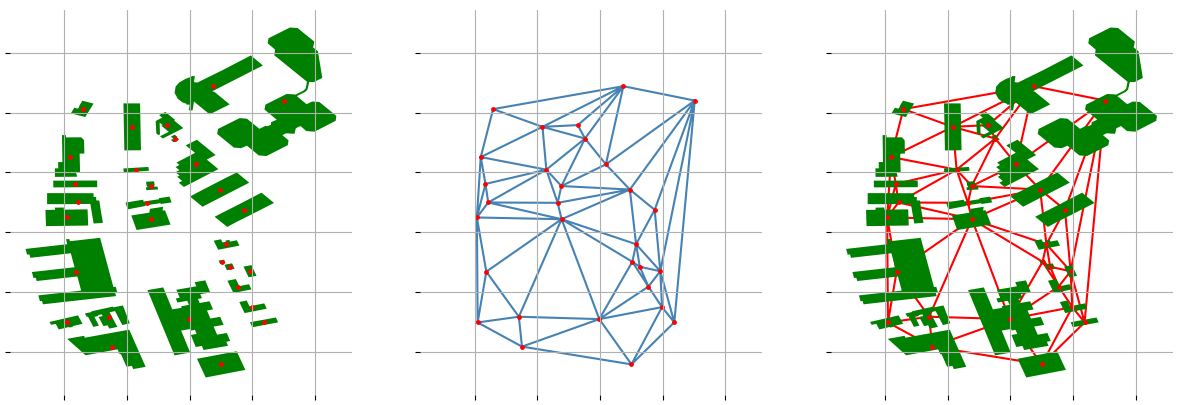
When simple triangulation is not enough
In some cases triangulation doesn't help - for example, when there are many small buildings in the area - every building still has way too many neighbors. And that raises another question: how to reduce the number of neighbors without losing too much information? For now, I decided to try three most obvious methods: unary_union, unary_union with adding a buffer and limiting the number of neighbors.
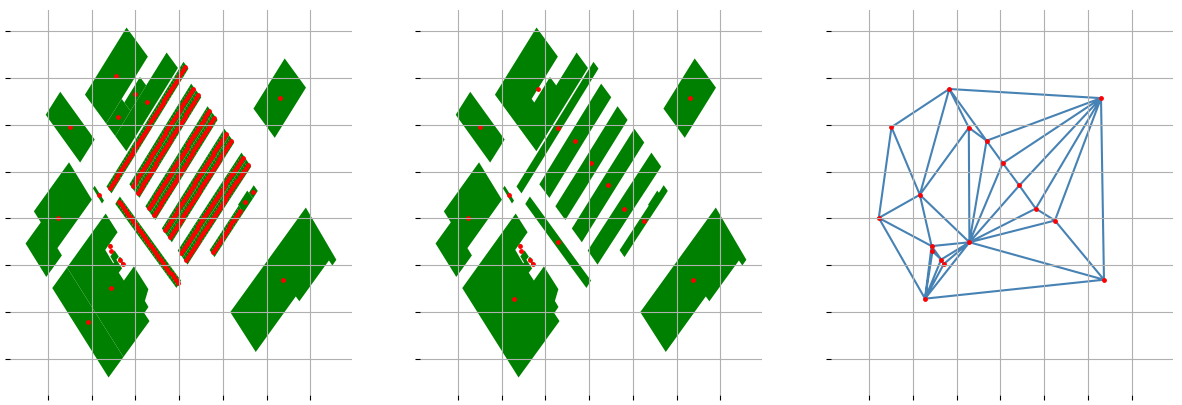

Which method to use? All of them, depending on how well the previous method worked: if simple triangulation fails, try unary_union merging. If simple unary_union fails, try adding a buffer and then merging. If all of them fail, then just limit the number of objects in a group when selecting the neighbors.
Other methods I tried
I also tried to use the DBSCAN-based clustering methods: clustering based on centroids or spatial distance. Unfortunately, it took me too much time to find the somewhat good parameters and most of the results looked like the one on the image below:
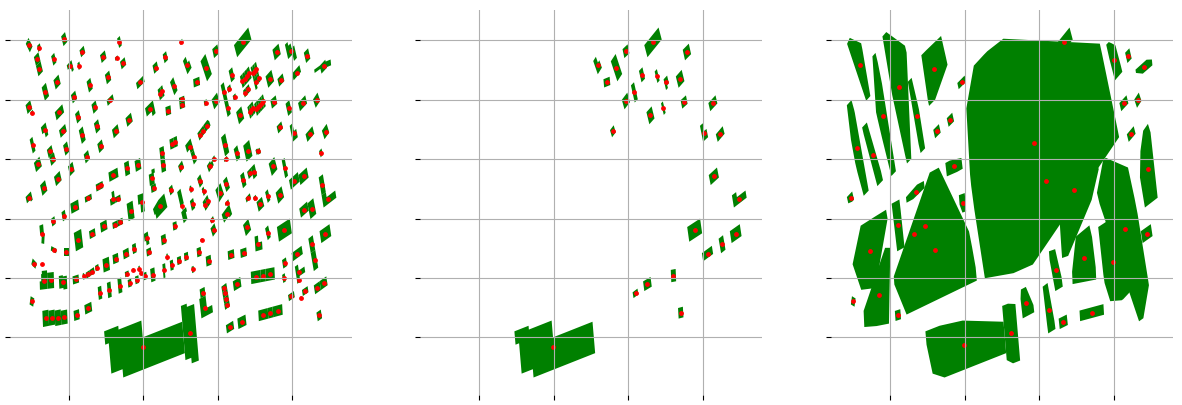
Summary
The final code looks like this: reduce number of buildings by joining adjacent or very close ones, then generate all possible combinations of those buildings.
def powerset(iterable):
s = list(iterable)
powerset = list(chain.from_iterable(combinations(s, r) for r in range(1, len(s) + 1)))
return powerset
def groupNeighbours(geoms):
tri = Delaunnay([(g.centroid.x, g.centroid.y) for g in geoms])
grouped = collections.defaultdict(set)
for i, j, k in tri.simplices:
grouped[i] |= {j, k}
grouped[j] |= {i, k}
grouped[k] |= {i, j}
return sorted(grouped.items())
# In case we want to preserve OSM data across transformations.
def map_union(original, grouped):
if not original or not grouped:
return []
tree = strtree.STRtree(original)
return [
(i, sorted(tree.query(component, predicate="intersects")))
for i, component in enumerate(grouped)
]
def get_neighbors(geoms: list[Geometry]) -> list[tuple[int, ...]]:
if len(geoms) < 4:
return powerset(range(len(geoms)))
grouped = groupNeighbours(geoms)
return list(
set(
tuple(sorted(subgroup))
for root, other in grouped
for subgroup in powerset({root} | other)
)
)
In the end, I was able to reduce the number of buildings and variants to an acceptable level. For example, the area around Biel/Bienne contains 1240 buildings, which gives 2^1240 possible combinations, but after grouping and triangulation, the number of combinations reduced to:
- ~35000 for triangulation with unary_union
- ~3728 for triangulation with buffer and unary_union